The story behind this paper dates back to 2014 when Michael Petr, a junior research scientist doing his post-bachelor fellowship at the National Institute on Aging (NIA), NIH, joined Insilico Medicine, a young artificial intelligence (AI) startup at the Emerging Technology Centers in Baltimore as an intern. At the NIA, he was working under the supervision of Morten Scheibye-Knudsen, MD, PhD. He introduced his bosses who both shared deep interest in aging and age-associated diseases, which led to the years of close collaborations, the development of a largest industry conference in aging, the ARDD, and a wonderful friendship. When Morten came back to Copenhagen, he invited Michael to the University. Michael followed and successfully defended his PhD in the Scheibye-Knudsen lab. He later established an aspiring startup “Tracked Bio”, focusing on artificial intelligence-based biomarkers of aging. The Scheibye-Knudsen lab grew and developed deeper expertise in bioinformatics and machine learning. In 2018 Garik Mkrtchyan, who got his PhD in bioinformatics, joined the lab as a Postdoctoral Fellow. Garik was intimately familiar with Insilico Medicine’s algorithms and was a power user of its PandaOmics target discovery platform.
PandaOmics is an AI-driven target discovery platform developed by Insilico Medicine, that applies deep learning models to identify therapeutic targets associated with a given disease through a combination of omics data analysis put in the context of prior information coming from publications, clinical trials and grant applications. The algorithm optimizes for the best potential therapeutic targets by scoring results on factors such as: novelty, confidence, commercial tractability, druggability, safety, and other key properties that drive target selection decisions. PandaOmics has been used to identify new targets for cancer, amyotrophic lateral sclerosis (ALS) and COVID-19, among other diseases, with the novel target it discovered for idiopathic pulmonary fibrosis has been developed into a lead drug candidate (designed through Insilico Medicine’s Chemistry42 AI platform) that is currently in Phase 1 clinical trials, the first AI-discovered and AI-designed drug to reach this milestone.
Here is the story of how PandaOmics was developed - from its early days as a theoretical algorithm to a validated new means for identifying novel targets - and then applied to study DNA repair-associated disorders in order to find novel cancer biomarkers.
The evolution of iPANDA into PandaOmics
PandaOmics had its start in 2016, when Insilico Medicine published what was called the Insilico Pathway Activation Network Decomposition Analysis (iPANDA) algorithm for biology-justified dimensionality reduction.The algorithm allowed researchers to quickly and efficiently analyze signaling and metabolic pathway perturbation states using gene expression data.
A team from Insilico Medicine worked with collaborators from the Johns Hopkins University, Albert Einstein College of Medicine, Boston University, Novartis, Nestle and BioTime to demonstrate that iPANDA provided significant noise reduction in transcriptomic data and identified highly robust sets of biologically relevant pathway signatures for breast cancer patients according to their sensitivity to neoadjuvant therapy. Breast cancer is the second most common cancer in the U.S. and the second leading cause of cancer death in women. It represents a large unmet need for the development of new highly robust transcriptomic data analysis methods. The results from this research were published in Nature Communications in November 2016.
Notably, iPANDA method of transcriptomic data analysis on the signaling pathway level was not only useful for discrimination between various biological or clinical conditions, but could also aid in identifying functional categories or pathways that may be relevant as possible therapeutic targets.
Once we had established a proven means of identifying relevant biological pathways for diseases, we began to expand the system’s predictive capabilities through additional data, both from existing sources and from our own experiments.
From 2016 until PandaOmics was officially launched in 2020, Insilico Medicine published broadly in leading scientific journals as it further expanded its target discovery capabilities. A paper published in 2016 by the American Chemical Society showed that Insilico’s deep learning applications could be used to predict the pharmacological properties of drugs across different biological systems and conditions using transcriptomic data. The same year, a collaborative study with researchers from Johns Hopkins University and Moffitt Cancer Center published in Clinical Cancer Research, implicated that JNK and MAPK pathway activation mediate cetuximab resistance in head and neck cancer patients with low SMAD4 expression, providing the foundation for concomitant EGFR and JNK/MAPK inhibition as a strategy for overcoming cetuximab resistance in cases with SMAD4 loss (https://aacrjournals.org/clincancerres/article/23/17/5162/123028/SMAD4-Loss-Is-Associated-with-Cetuximab-Resistance).
In 2017, iPANDA was used to assess a network of molecular signaling in oral cancer and pre-neoplastic oral lesions, revealing the key driving pathways of early stages of head and neck tumorigenesis. This study was included in a collection of Top 25 articles published in Cell Death Discovery (https://www.nature.com/articles/cddiscovery201722).
In 2018, the Insilico team used iPANDA to identify bifunctional immune checkpoint-targeted antibody-ligand traps for cancer immunotherapy – results were published in Nature Communications. In a 2019 manuscript published in Oral Oncology, iPanda highlights pathways and genetic events that may serve as candidate biomarkers and novel targeted therapies to enhance the efficacy of immunotherapy in head and neck cancer patients (https://pubmed.ncbi.nlm.nih.gov/31422218/). The same year, a study published in Springer showed how the algorithm could discern aberrantly activated signaling events in gallbladder cancer and found that PIM1 could be a therapeutic target.

In 2020, PandaOmics was officially launched, drawing on trillions of data points, built up over the intervening years. This includes 5 million omics data samples, including transcriptomics, genomics, epigenomics, proteomics, and single cell data generated by the scientific community; 1.3 million compounds and biologics; 3.8 million patents; over $1 trillion in grants; 342,000 clinical trials; and over 30 million publications.
PandaOmics begins with iPANDA’s, a proprietary pathway analysis developed to infer pathway activation or inhibition. Then, its AI algorithm analyzes all data and significant genes from an experiment in the context of the disease being studied and identifies a number of actionable drug target hypotheses. The system next evaluates the targets using molecular and text evidence and predicts the likelihood of that target entering Phase 1 clinical trials within the next five years. PandaOmics also predicts the “hotness” of a particular target based on the attention it is receiving in the scientific community.
In 2021, Insilico team in collaboration with researchers from the University of Chicago performed a comprehensive transcriptome-based computational analysis on data from hundreds of patients with head and neck squamous cell carcinoma, and discovered that high DLCK1 expression positively correlates with NOTCH signaling pathway activation and could serve as a potential therapeutic target. The study was published in Frontiers in Oncology. This collaboration has also led to a study published in Cell Reports Medicine, providing evidence that induction of a T cell-inflamed phenotype via therapeutic manipulation of Treg cells may trigger unexpected tumor-promoting effects in oral cancer and other solid malignancies (https://www.sciencedirect.com/science/article/pii/S2666379121002573?via%3Dihub).In just two months’ time, Insilico also used PandaOmics to uncover multiple targets specific to both aging and disease, a finding that could lead to the development of dual-purpose therapeutics. Identifying such targets could provide added effectiveness for older patients who are suffering from disease, as well as delaying or reversing certain aging processes in addition to treating disease symptoms. In a recent study, InSilico deployed PandaOmics to perform target identification for 14 age-associated diseases and 19 non-age-associated diseases across multiple disease areas to identify targets of age-associated diseases. PandaOmics revealed 145 genes that were considered potential aging-related targets and mapped these into corresponding aging hallmarks, including 69 high confidence targets with high druggability, 48 medium novel targets with high or medium druggability, and 28 highly novel targets with medium druggability. The results were published in March 2022 in the journal Aging.

A tool for pharma and academic researchers to accelerate their programs
Since it officially launched in 2020, PandaOmics has been employed by numerous top pharma companies and academic researchers to identify novel targets for their programs.
Pfizer entered into a research collaboration with Insilico in January 2020 to explore new targets for diseases with high unmet needs using PandaOmics. In August 2021, Insilico announced a research partnership with Arvinas to use PandaOmics to discover novel Proteolysis Targeting Chimeras (PROTACs). In January 2022, a collaboration agreement was announced between Insilico and Fosun Pharma to use PandaOmics to discover four biological targets and to co-develop a Glutaminyl-Peptide Cyclotransferase-Like Protein (QPCTL) program at Insilico.
According to the collaboration agreement, Insilico will deliver a preclinical candidate for the QPCTL program and advance it to the IND stage, after which Fosun Pharma will conduct human clinical studies and co-develop the candidate globally. In parallel, Fosun Pharma's R&D team will nominate four therapeutic targets to be assessed by Insilico's AI platform and R&D team, who are responsible for advancing these drug candidates to the IND stage.
Insilico’s PandaOmics AI target discovery platform was also recently used by a consortium of top ALS researchers from Harvard, Johns Hopkins, Mayo Clinic, University of Chicago, Shanghai University and other institutions, in order to find new targets for the debilitating neuromuscular disease. The platform drew on comprehensive patient data collected by the research group Answer ALS. The AI software found 17 high-confidence and 11 novel therapeutic targets. The results were published in June 2022 in the journal Frontiers in Aging Neuroscience.

Advancing the first AI-discovered and AI-designed drug to human trials
Among the platform’s most important advances in end-to-end AI drug discovery has been the identification of Insilico Medicine’s lead drug candidate for treating idiopathic pulmonary fibrosis. In just 18 months, PandaOmics discovered a novel pan-fibrotic target and Insilico’s AI drug design platform, Chemistry42, predicted a novel corresponding drug candidate for 1/10th of the typical cost associated with typical drug development. PandaOmics sorted through millions of data files, including patents, research publications, grants, and databases of clinical trials, and revealed 20 potential targets for Idiopathic Pulmonary Fibrosis (IPF). The targets were then narrowed down to one novel intracellular target that was prioritized for further analysis.
The lead drug candidate has since went through extensive target validation, and is currently in a Phase 1 trials in New Zealand and China, the first AI-discovered and AI-designed drug to reach this milestone.
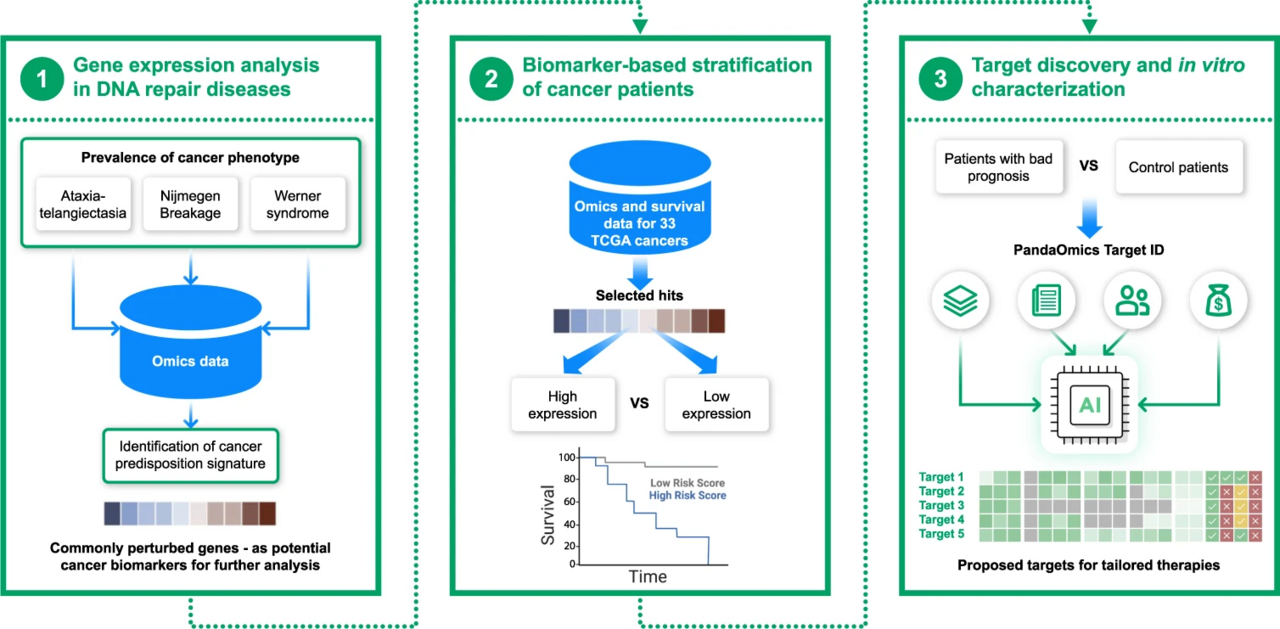
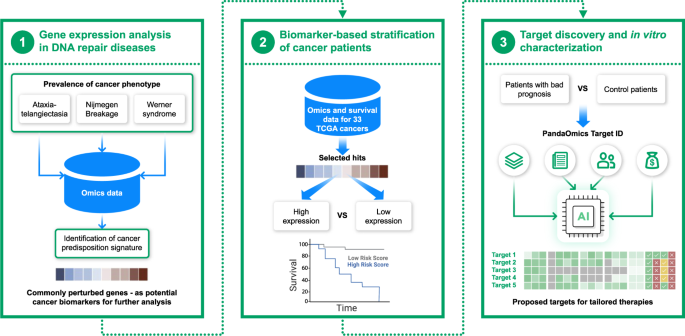
PandaOmics to give a new life to oncology targets by studying rare genetic DNA repair deficiencies
The number one question in the oncology field is how to enroll the patients to the clinical trials that are assumed to most likely respond to the therapy. There are plenty of targets for certain diseases with strong biological evidence behind them, but the vast majority of these targets do not reach clinical efficacy endpoints. One reason might be due to poor recruitment strategy, which highlights the significance of the usage of molecular biomarkers to improve patients’ selection criteria. Patients with histologically and clinically identical cancer have different biology, mediated by unique molecular profile, meaning that a single drug will not work for all. As such, the field shifts towards recruiting the right patients with the right molecular profile to the trial, which we hope will increase the chances of the larger number of patients in the trial to respond to the therapy. This is exactly what our paper demonstrates - cancer patients can be stratified by using the novel omics-driven biomarkers.
While key cancer-driving biomarkers are known for quite a long time, quite often investigators keep comparing the cancer patients with healthy individuals, in order to identify new molecular signatures that separate them. It is well known that dysregulation of DNA repair machinery is a distinct feature of all cancers. But focusing on cancer patients to study this dysregulation may ultimately identify the same markers again and again. What has been done in this paper is very different. Instead of going directly to the cancer patients, researchers have analyzed patients which do not have cancer, but do have the conditions that are driven by dysregulated DNA repair machinery, and identified what makes those patients different, especially those who have a higher predisposition to develop cancers. Then, our team applied this knowledge to the large dataset of cancer patients to identify cancer types in which these signatures stratify individuals by their survival outcomes. The similar strategy may be utilized for any cancer, as algorithms from PandaOmics tool and other analytical pipelines developed by Insilico Medicine are pathology-independent and can be easily adjusted to any disease.
The entire idea of applying PandaOmics to rare DNA repair deficiencies for identifying novel cancer biomarkers is a result of the long-standing collaboration between Insilico Medicine, University of Copenhagen and University of Chicago. Diseases can be stratified based on the phenotypic traits, and the molecular basis of many of these diseases is known. However, we do not necessarily know the reason why phenotypes develop. Some of the diseases that we clustered lead to cancer and some of them do not. Patients with three diseases that we analyzed are known to develop cancer, so there is a large phenotypic overlap (meaning that all that is overlapping between those 3 disorders can be hypothesized to be somehow related to cancer). As such, we assumed that analysis of these disorders and identification of cancer predisposition signature might be a good starting point for the identification of novel cancer biomarkers. We used PandaOmics platform for the identification of cancer predisposition signatures and found that some of them might be used as predictive biomarkers for patients with poor survival. Focusing on a group of sarcoma patients with a bad prognosis, we applied PandaOmics AI-powered Target ID engine to identify several targets for the group of sarcoma patients with poor prognosis. Among them, PLK1 was predicted as a potential target, which was further tested and validated in in vitro experiments. It is important to mention that PLK1 was recently proposed as a target for the treatment of sarcoma, albeit potent PLK1 inhibitor showed limited antitumor activity in recruited patients. Presumably, poor recruitment strategy was one of the reasons the trial failed to reach its efficacy endpoints, further highlighting the importance of the identification and usage of molecular biomarkers for the stratification of cancer patients.

This study serves as an ultimate use case of applying PandaOmics to biomarker development and provides evidence of the possibility to develop advanced tailored therapies improving the outcomes of sarcoma patients and hence giving the second life to the targets like PLK1. The application of AI-powered approaches such as PandaOmics may facilitate this strategy not only for cancer but also for a broader range of age-associated diseases.
Please watch our Behind the Paper Episode on Youtube, where we discussed this paper, our story, and future papers and collaborations.





Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in